
Young Researcher Paper Award 2025
🥇Winners
🥇Winners
Print: ISSN 0914-4935
Online: ISSN 2435-0869
Sensors and Materials
is an international peer-reviewed open access journal to provide a forum for researchers working in multidisciplinary fields of sensing technology.
Online: ISSN 2435-0869
Sensors and Materials
is an international peer-reviewed open access journal to provide a forum for researchers working in multidisciplinary fields of sensing technology.
Tweets by Journal_SandM
Sensors and Materials
is covered by Science Citation Index Expanded (Clarivate Analytics), Scopus (Elsevier), and other databases.
Instructions to authors
English 日本語
Instructions for manuscript preparation
English 日本語
Template
English
Publisher
MYU K.K.
Sensors and Materials
1-23-3-303 Sendagi,
Bunkyo-ku, Tokyo 113-0022, Japan
Tel: 81-3-3827-8549
Fax: 81-3-3827-8547
MYU Research, a scientific publisher, seeks a native English-speaking proofreader with a scientific background. B.Sc. or higher degree is desirable. In-office position; work hours negotiable. Call 03-3827-8549 for further information.

MYU Research
(proofreading and recording)

MYU K.K.
(translation service)

The Art of Writing Scientific Papers
(How to write scientific papers)
(Japanese Only)
is covered by Science Citation Index Expanded (Clarivate Analytics), Scopus (Elsevier), and other databases.
Instructions to authors
English 日本語
Instructions for manuscript preparation
English 日本語
Template
English
Publisher
MYU K.K.
Sensors and Materials
1-23-3-303 Sendagi,
Bunkyo-ku, Tokyo 113-0022, Japan
Tel: 81-3-3827-8549
Fax: 81-3-3827-8547
MYU Research, a scientific publisher, seeks a native English-speaking proofreader with a scientific background. B.Sc. or higher degree is desirable. In-office position; work hours negotiable. Call 03-3827-8549 for further information.
MYU Research
(proofreading and recording)
MYU K.K.
(translation service)
The Art of Writing Scientific Papers
(How to write scientific papers)
(Japanese Only)
Sensors and Materials, Volume 34, Number 7(4) (2022)
Copyright(C) MYU K.K.
Copyright(C) MYU K.K.
|
pp. 2809-2819
S&M3007 Research Paper of Special Issue https://doi.org/10.18494/SAM3921 Published: July 28, 2022 Recognition System for Cantonese Speakers in Different Noisy Environments Based on Estimate–Maximize Algorithm [PDF] Yu Fan, Chin-Ta Chen, and Cheng-Fu Yang (Received March 29, 2022; Accepted May 24, 2022) Keywords: speaker identification, estimate–maximize algorithm, Gaussian mixture model, Mel-frequency cepstrum coefficient, maximum likelihood estimation
Highly accurate personal identification systems are required in many different recognition situations. In this study, the Mel-frequency cepstrum coefficient was used to extract the features of speakers. The aim of this study was to identify different speeches in different noisy environments. A maximum likelihood estimation method based on noise probability was proposed to enhance the recognition effects of the Gaussian mixture model of different speeches from mixed noise speech signals. Experimental results indicated that the method had high recognition results under various noise conditions. The recognition results of the proposed method in different noise environments were superior to those of a method using only one type of noise for modeling. Experimental results obtained from some unspecified speakers showed that three different languages (Mandarin, English, and Cantonese) were effectively identified.
Corresponding author: Yu Fan, Cheng-Fu Yang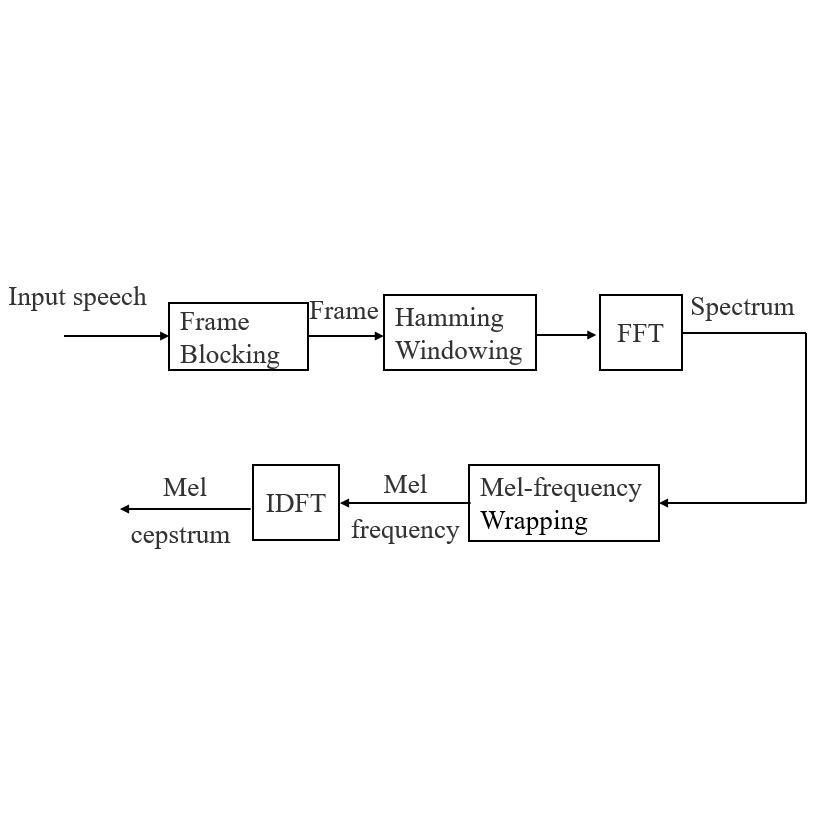  This work is licensed under a Creative Commons Attribution 4.0 International License. Cite this article Yu Fan, Chin-Ta Chen, and Cheng-Fu Yang, Recognition System for Cantonese Speakers in Different Noisy Environments Based on Estimate–Maximize Algorithm, Sens. Mater., Vol. 34, No. 7, 2022, p. 2809-2819. |
Forthcoming Regular Issues
Forthcoming Special Issues
Special Issue on Signal Collection, Processing, and System Integration in Automation Applications 2026
Guest editor, Hsiung-Cheng Lin (National Chin-Yi University of Technology), Ming-Te Chen (National Chin-Yi University of Technology), and Chin-Yi Cheng (National Yunlin University of Science and Technology)
Call for paper
Special Issue on Advanced GeoAI for Smart Cities: Novel Data Modeling with Multi-source Sensor Data
Guest editor, Prof. Changfeng Jing (China University of Geosciences Beijing)
Call for paper
Special Issue on Advanced Sensor Application Development
Guest editor, Shih-Chen Shi (National Cheng Kung University) and Tao-Hsing Chen (National Kaohsiung University of Science and Technology)
Call for paper
Special Issue on Sensing Beyond Transduction: Materials, Devices, and Signal Processing for Intelligent Sensory Systems
Guest editor, Masayuki Sohgawa (Niigata University)
Call for paper
Special Issue on Advanced Materials and Technologies for Sensor and Artificial- Intelligence-of-Things Applications (Selected Papers from ICASI 2026)
Guest editor, Sheng-Joue Young (National Yunlin University of Science and Technology)
Conference website
Call for paper
Special Issue on Biosensing Devices
Guest editor, Kiyotaka Sasagawa (Nara Institute of Science and Technology)
Call for paper
-
For more information of Special Issues (click here)
-
Special Issue on Mobile Computing and Ubiquitous Networking for Smart Society
- Accepted papers (click here)
- High-precision Autonomous Driving Map Quality Inspection Indicator System and Evaluation Method
Chengcheng Li, Ming Dong, Hongli Li, Xunwen Yu, Yongxuan Liu, and Chong Zhang - Surface Albedo in Different Land Cover Types in Northeast China
Tao Pan, Fu Li, Yucheng Tao, Lijuan Zhang, and Xiaoyan Jiang
- High-precision Autonomous Driving Map Quality Inspection Indicator System and Evaluation Method
- Accepted papers (click here)
- Negative Temperature Coefficient Thermistor with Multilayer Thin-film Structure AlN/VOx/AlN on Si(100) Substrate
Chen-Hung Yen, Ing-Jiunn Su, and Hui-Huang Hsieh
- Negative Temperature Coefficient Thermistor with Multilayer Thin-film Structure AlN/VOx/AlN on Si(100) Substrate
- Accepted papers (click here)
- Design and Development of a Fuzzy-logic-based Long-range Aquaculture System
Sheng-Tao Chen and Tai-I Chou
- Design and Development of a Fuzzy-logic-based Long-range Aquaculture System
Guest editor, Akira Uchiyama (The University of Osaka) and Jaehoon Paul Jeong (Sungkyunkwan University)
Call for paper
Special Issue on Novel Sensors, Materials, and Related Technologies on Artificial Intelligence of Things Applications
Guest editor, Teen-Hang Meen (National Formosa University), Wenbing Zhao (Cleveland State University), and Cheng-Fu Yang (National University of Kaohsiung)
Call for paper
Special Issue on Low-altitude Economy: Technologies, Infrastructure, and Applications
Guest editor, He Huang and Junxing Yang (Beijing University of Civil Engineering and Architecture)
Call for paper
Special Issue on Multisource Sensors for Geographic Spatiotemporal Analysis and Social Sensing Technology Part 5
Guest editor, Prof. Bogang Yang (Beijing Institute of Surveying and Mapping) and Prof. Xiang Lei Liu (Beijing University of Civil Engineering and Architecture)
Special Issue on Materials, Devices, Circuits, and Analytical Methods for Various Sensors (Selected Papers from ICSEVEN 2026)
Guest editor, Chien-Jung Huang (National University of Kaohsiung), Mu-Chun Wang (Minghsin University of Science and Technology), Shih-Hung Lin (Chung Shan Medical University), Ja-Hao Chen (Feng Chia University)
Conference website
Call for paper
Special Issue on Sensing and Data Analysis Technologies for Living Environment, Health Care, Production Management, and Engineering/Science Education Applications (2026)
Guest editor, Chien-Jung Huang (National University of Kaohsiung), Rey-Chue Hwang (I-Shou University), Ja-Hao Chen (Feng Chia University), Ba-Son Nguyen (University of Economics Ho Chi Minh City)
Call for paper
Special Issue on Multisource Sensors for Resource and Environmental Monitoring: Theories, Models, Methods, and Application
Guest editor, Chao Chen (Suzhou University of Science and Technology)
Call for paper
Special Issue on Spatial Intelligence, Digital Twins, and AI-driven Smart Systems for Next-Generation Built Environment
Guest editor, Jaekang Lee (Dong-A University), Myeong Hun Jeong (Chosun University), and Dong Ha Lee (Kangwon National University),
Call for paper
Special Issue on Advances in Sensors and Computational Intelligence for Industrial Applications: Part 2 (submission closed)
Guest editor, Chih-Hsien Hsia (National Ilan University)
Call for paper
Special Issue on Intelligent Sensing and AI-driven Optimization for Sustainable Smart Manufacturing
Guest editor, Cheng-Chi Wang (National Sun Yat-sen University)
Call for paper
- Accepted papers (click here)
Copyright(C) MYU K.K. All Rights Reserved.